
MTBF Explained: What It Is, How to Calculate It, and Why Reliability Teams Swear By It
Maintenance leaders are usually buried under a mountain of data, but still end up needing more actual insights. You know which machines broke down yesterday, but do you know which one is guaranteed to fail next month?
This is where understanding Mean Time Between Failures (MTBF) becomes the difference between a reactive firefighting culture and a strong reliability program.
MTBF isn't just a math for reliability engineers; it is a real scan of your operational health. When calculated correctly using asset history, it tells you how long your equipment typically stays in the fight before needing a timeout.
Let’s break down the mechanics of MTBF, why your current calculations might be lying to you, and how to use this metric to transform your preventive maintenance planning.
Key takeaways
- What it measures: The average operational uptime between unplanned mechanical or electrical failures.
- The goal: A higher MTBF indicates a more reliable asset. It helps you transition from firefighting to data-driven preventive maintenance planning.
- The formula: Divide total operating time by the number of failures.
- The "data trap": Your MTBF is only as accurate as your asset history. If technicians aren't logging every small reset or jam in your CMMS, your reliability metrics will be artificially inflated.
- Strategic value: Use MTBF to "right-size" your PM intervals, build a business case for asset replacement, and hold equipment OEMs accountable for performance.
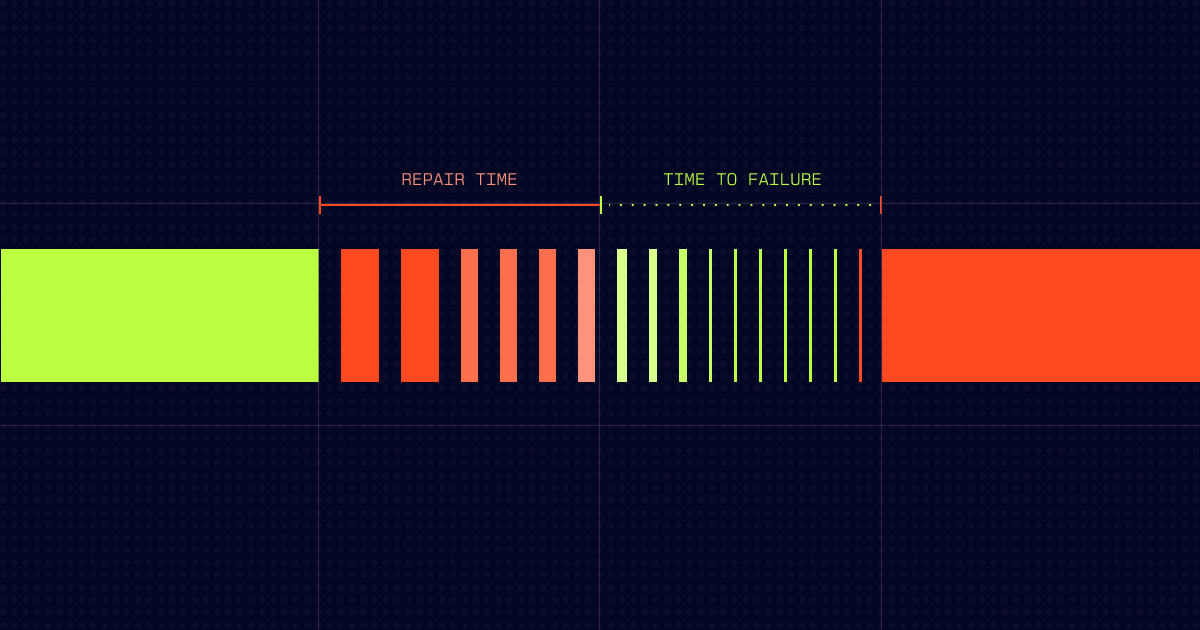
What is MTBF (Mean Time Between Failures)?
At its core, MTBF is a reliability metric that measures the average elapsed time between inherent failures of a mechanical or electronic system during normal system operation.
It’s important to distinguish that MTBF only applies to repairable items. If a lightbulb burns out and you throw it away, you are looking at Mean Time to Failure (MTTF). But for a centrifugal pump, a CNC machine, or an HVAC unit (assets you repair to extend their life), MTBF is your primary metric for asset reliability.
The MTBF formula
To calculate MTBF, you divide the total functional uptime of an asset by the number of failures that occurred during that same period.
MTBF = Total operating time / Number of failures
For example, if a packaging line runs for 1,000 hours in a quarter and suffers 5 breakdown events, the MTBF is 200 hours. This means, on average, you can expect 200 hours of productive work before the next unplanned interruption.
Why MTBF matters for reliability leaders
Tracking MTBF serves three functions for a maintenance department. Without it, you are essentially guessing where to allocate your most important resources: time and budget.
1. Predict equipment reliability
MTBF provides a baseline for "normal." If a motor has a historical MTBF of 2,100 hours and it suddenly drops to 800 hours, you have an indicator that something has changed. Maybe a recent batch of spare parts was subpar, or the operating conditions have become more strenuous. It allows you to spot trends before they result in a catastrophic "line-down" event.
2. Improve preventive maintenance scheduling
Many teams perform preventive maintenance (PM) based on arbitrary manufacturer recommendations or "the way we've always done it." This usually leads to over-maintaining assets, which wastes labor and introduces "infant mortality" defects.
By knowing your MTBF, you can time your PMs to happen just before the statistical likelihood of failure increases, optimizing your schedule for maximum uptime.
3. Support asset replacement planning
Eventually, every asset reaches a point of diminishing returns. As an asset nears the end of its equipment life cycle, the MTBF usually starts to shrink. When you can show leadership a graph of a declining MTBF alongside rising repair costs, you have a data-driven business case for asset replacement instead of another band-aid repair.
{{benchmark-report="/components"}}
The data requirements for accurate MTBF
The biggest hurdle to calculating a meaningful MTBF isn't the math—it’s the data discipline. If your team isn't capturing every blip in the system, your MTBF will look artificially high, leading to a false sense of security.
Complete work capture
Reliability analysis needs a "closed-loop" system. Every time a machine stops unexpectedly, a work order must be generated.
High-discipline teams using a CMMS usually capture 82% or more of all maintenance work, whereas low-discipline teams may only log 45%. If half of your failures are handled via unrecorded repairs, your MTBF metrics are basically useless.
Structured failure coding
Knowing that a machine failed is a start; knowing why is better.
Using structured failure codes allows you to calculate MTBF for specific failure modes. This level of detail helps reliability engineers pinpoint the bad actors in a complex system.
Asset-level history
Data has to be tied to a specific asset, not a general department or floor. A robust asset history allows you to compare identical machines in different environments.
If Pump A has an MTBF of 4,000 hours in a climate-controlled room, but Pump B (the same model) has an MTBF of 1,200 hours in a humid wash-down area, you’ve identified an environmental reliability factor.
Why many MTBF calculations are wrong
In many plants, MTBF is a vanity metric, aka it looks good on a report but doesn't reflect reality. Here are the common pitfalls that lead to inaccurate reporting.
Missing work order data
If a technician spends 15 minutes clearing a jam or resetting a sensor without creating a digital record, that downtime is lost to the ether. When you calculate MTBF at the end of the month, the "Number of failures" (the denominator in our formula) is too low, making the asset seem more reliable than it actually is.
Informal repairs never logged
In high-pressure environments, the priority is "get it running." This often leads to informal fixes that skip the CMMS entirely. Without these records, you lose the ability to see the frequency of small, nagging issues that usually come before major failures.
Inconsistent failure definitions
What constitutes a "failure"? Is it only when the machine stops entirely, or is it a failure if it's running at 50% capacity because of a faulty component? Without a clear, standardized definition of failure across the maintenance and operations teams, your data will be inconsistent.
How MTBF connects to other maintenance metrics
MTBF doesn't live in a vacuum. To get a full picture of your facility's health, you should look at it alongside other reliability metrics.
Step-by-Step: Implementing an MTBF improvement program
If you want to move the needle on MTBF, follow this structured approach:
- Standardize failure definitions: Meet with Operations and Maintenance to agree on what counts as a failure event.
- Audit your CMMS usage: Make sure technicians can easily log work orders from the floor. If it's too hard to log a small failure, they won't do it.
- Identify "bad actor" assets: Run a report to find the 5 assets with the lowest MTBF in your facility.
- Perform Root Cause Analysis (RCA): For those 5 assets, dig into the failure history. Are the failures mechanical, electrical, or operational?
- Adjust PM checklists: If an asset is failing every 300 hours, but your PM is scheduled every 500 hours, move the PM to a 250-hour interval or investigate a more durable component.
- Monitor and iterate: Re-evaluate the MTBF for those assets after 90 days. Did the changes increase the time between failures?
Real-world scenario: The case of the overheated gearbox
A mid-sized food processing plant notices that its primary conveyor system has a declining MTBF, dropping from 600 hours to just 150 hours over six months.
Initially, the team might blame the age of the equipment. However, by looking at the asset history in a CMMS like Limble, they will realize that the failures were almost always related to gearbox overheating.
Further investigation will reveal that a change in the cleaning chemical used during wash-downs was degrading the seals, leading to oil leaks and subsequent overheating.
By identifying the trend through MTBF and specific failure coding, they can replace the seals with a chemically resistant material. The MTBF will rebound to 700 hours, saving the company in emergency repair costs and lost production.
Checklist: Is your MTBF data reliable?
Before you present MTBF numbers to your Plant Manager, run through this checklist to make sure your data is defensible:
- Every unplanned stop longer than 5 minutes has a corresponding work order.
- "Total operating time" accounts for actual run-time, not just 24/7 calendar time.
- Maintenance technicians have a mobile tool to log failures instantly at the machine.
- Failure codes are used on at least 90% of unplanned work orders.
- PMs are triggered by usage (hours/cycles) rather than just calendar dates where possible.
- You have a clear process for excluding external failures (like power grid outages) from asset reliability math.
Using MTBF to improve maintenance strategy
The ultimate goal of tracking MTBF is to transition from a "fix it when it breaks" mindset to a strategic asset management approach.
When you have a high-definition view of your failure patterns, you can start implementing condition-based maintenance. Instead of guessing when a failure might happen, you use MTBF data to set thresholds for vibration sensors or ultrasound kits.
MTBF also allows you to hold OEMs (Original Equipment Manufacturers) accountable. If you purchase a new piece of equipment that’s rated for a specific MTBF and it underperforms in your environment, you have the hard data necessary to negotiate support or future discounts.
From MTBF to asset intelligence
MTBF is a foundational stone, but it is just one part of a larger "Asset Intelligence" framework. Strategic asset management needs moving beyond just averages and looking at the entire equipment life cycle.
When you combine MTBF with cost-to-maintain data and labor utilization, you begin to see the true Total Cost of Ownership for your assets. This is where maintenance stops being a cost center and starts being a competitive advantage for the business. Organizations that master these metrics are the ones that can scale production without a proportional increase in maintenance headcount.
To really excel, you need a system that makes this data collection invisible to the technician but invaluable to the manager. By capturing structured failure data at the source, you ensure that your reliability metrics actually reflect the reality of the shop floor.
[Link to the anchor guide or cute site component that we can ask Jim can make]
Quick maths
Understanding and optimizing MTBF is essential for any organization aiming for high asset reliability. By measuring the average time between unplanned events, maintenance leaders can move away from reactive chaos and toward a predictable, data-driven strategy.
As you now know, the value of MTBF lies in its ability to inform preventive maintenance planning, justify asset replacements, and highlight systemic issues in your operation. However, the metric is only as good as the data fed into it.
Whether you are just starting to track reliability metrics or you are looking to refine an existing program, focusing on MTBF will provide the clarity needed to reduce downtime and extend the life of your critical assets.
Start small, clean up your data, and let the numbers guide your path to operational excellence.
Ready to see how your reliability metrics stack up against the best in the industry? Download our 2026 Maintenance Benchmark Report to compare your MTBF and uptime stats with leading organizations and discover the strategies they use to stay ahead.
FAQs
Q: What is the difference between MTBF and MTTR?
A: While MTBF measures the frequency of failures, Mean Time to Repair (MTTR) measures the average time it takes to get an asset back up and running after a failure occurs. MTBF is a measure of reliability, and MTTR is a measure of maintainability. Both are important for understanding total downtime. If you have a high MTBF but a very long MTTR, your facility can still suffer significant production losses from a single event.
Q: How do I use MTBF for preventive maintenance planning?
A: You can use MTBF to "right-size" your PM intervals. If your MTBF for a specific component is 1,000 hours, scheduling a PM every 800 hours ensures you are intervening before a failure is likely to occur. This data-driven approach prevents you from performing maintenance too early (wasting resources) or too late (allowing a breakdown).
Q: Does MTBF include scheduled downtime for maintenance?
A: No. MTBF specifically tracks the time an asset is performing its intended function between unplanned failures. Scheduled downtime for PMs or inspections is not counted as a "failure," and that time is usually excluded from the Total Operating Time in the calculation. Including scheduled stops would skew the metric and make the asset appear less reliable than it actually is.
Q: Why is asset history important for calculating MTBF?
A: Asset history provides the longitudinal data necessary to see trends. A single MTBF calculation is a snapshot; a history of MTBF over two years shows you if an asset is degrading. Without a detailed history in a CMMS, you can’t accurately account for all past failures or the exact number of operating hours, leading to "guesstimates" instead of reliable metrics.
Q: What is a "good" MTBF?
A: There is no universal "good" number for MTBF because it’s dependent on the asset type and industry. A "good" MTBF for a jet engine is measured in thousands of hours, while a "good" MTBF for a high-speed packaging sensor might be much lower. The goal isn’t to hit a specific industry number, but to consistently improve your own baseline over time.
Q: Can MTBF help with spare parts inventory?
A: Yes. By knowing how often a specific part fails (its MTBF), you can optimize your inventory levels. If you know a bearing has an MTBF of six months, and you have ten of those machines, you can predict with high confidence how many bearings you will need to stock annually, reducing carrying costs and avoiding stockouts.



.png)
